Review of MALLET, produced by Andrew Kachites McCallum
Shawn Graham and Ian Milligan
MALLET Version: 2.0.7
Requirements: Java
Reviewed: 15 February 2013
Tested on: Mac OS X v. 10.8.2, and Windows 7
The MAchine Learning for LanguagE Toolkit, or MALLET, has been one of the “hottest” tools in digital humanities research. A product of the University of Massachusetts Amherst, written by Andrew McCallum and a team of collaborators, MALLET was originally released in 2002 but has received considerable renewed interest of late.[1] Fruitfully employing Latent Dirichlet Allocation [pdf], or LDA, MALLET can help navigate large bodies of information. It does so by finding clusters of words that frequently appear together, or “topics.” The algorithm imagines that any possible text or document within a corpus is a mixture of different topics; each topic is imagined to be a probability distribution of terms within and across that corpus. This leads to a variety of outputs, including lists of topics and their constituent words, and list of documents and their constituent topics. These results can often be astounding, and have even been (tongue-in-cheek) described as “magic.”
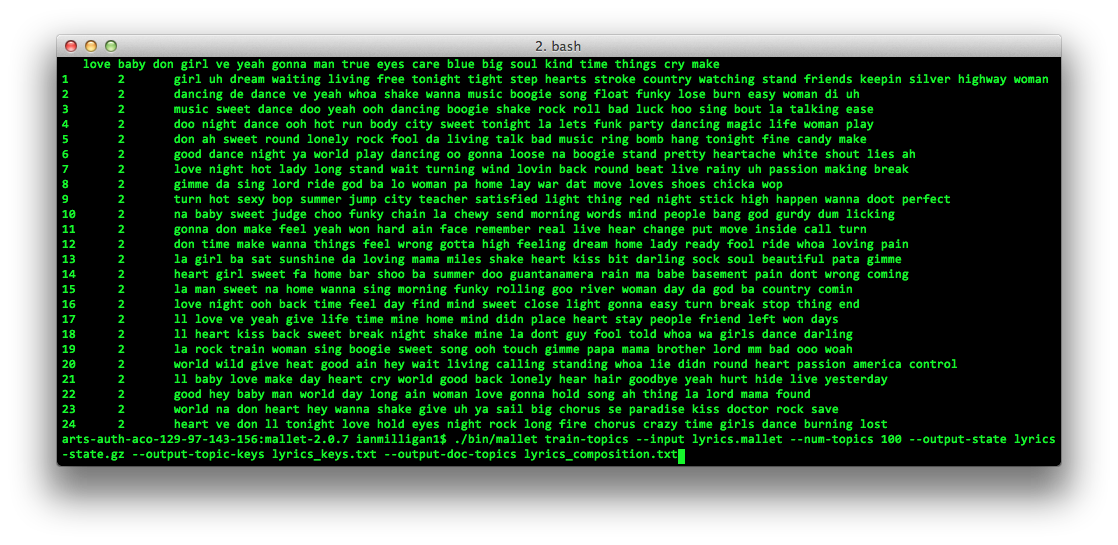
Figure 1: It isn’t pretty, but it works. The results of a topic model, showing 25 topics found across a database of nearly 15,000 song lyric files. At bottom is the command to execute yet another topic model, this time with 100 topics.
The possibilities of MALLET and topic modeling are best understood when seen in action (see also Templeton, 2011). In the humanities, some of the earliest uses of MALLET are Rob Nelson’s Mining the Dispatch and Cameron Blevins (2010) “Topic Modeling Martha Ballard’s Diary“. Elijah Meeks (2011) also explored the use of topic modeling a collection of blog posts, listserv messages, and articles to identify a definition of digital humanities. Matthew Jockers (2010) did the same for the 2010 Day of Digital Humanities. Newman and Block [pdf] (2006) explored similar techniques on a corpus of 18th century newspapers, but coded the algorithms themselves in Matlab. In 2009, in an example of the power of this method applied in a very different domain, David Mimno used topic modeling to understand the archaeology of a Pompeian house [pdf]. He imagined each room in the house could be read as a “document” and so the objects found within those rooms could be imagined as the “words”. The resulting topics from that analysis he argued constituted vocabularies of use, indicating the function of the rooms.
Topic modeling, and MALLET in particular, have wide appeal across the digital humanities. Historians can use it to take a large archival collection with robust OCR, run it through the system, and begin to see the overall contours and shape of the material. While it does not replace in-depth close reading, it does provide invaluable context and pointers towards issues that might have otherwise been missed. Literature scholars (such as Ted Underwood, Lisa Rhody and Jeff Drouin) have also fruitfully employed it to look through various narratives, seeing trends and issues throughout literary corpi.
The results produced by MALLET can be difficult to understand. For historians, some sense to the results can be injected when we consider the time dimension. In Nelson’s work, he plotted the resulting topics according to the date of publication of the original documents. Thus, he is able to tell a complex and nuanced story about, for instance, the interplay of fugitive slaves with the labour market of civil war Richmond:

Figure 2: The ‘fugitive slave ads’ topic versus the ‘for hire and wanted ads’ topic in Mining the Dispatch, by date.
Could it be that enslaved African American men and women destabilized the slave hiring market by using the chaos of war mobilization in and around Richmond to run away in increasing numbers? This is a question that can be formulated from but not answered by these graphs alone, that will require using more traditional research methods to investigate. But the question itself suggests the value of topic modeling. Topic modeling and other distant reading methods are most valuable not when they allow us to see patterns that we can easily explain but when they reveal patterns that we can’t, patterns that surprise us and that prompt interesting and useful research questions.[2]
Another way of visualizing the relationships suggested by MALLET’s output is to think of them as networks of ideas. It is trivial to turn a spreadsheet of documents-and-constituent-topics into a two-mode network visualization (document tied to topic), as Meeks does here (and Graham does here, using Gephi.) Ted Underwood explores in more depth other ways of visualizing topic model output here.
MALLET isn’t perfect. The most trenchant criticism of it is its steep learning curve. Indeed there are “hidden steps” (which perhaps form tacit knowledge for computer scientists and power users but can be completely opaque for humanists) — for instance, MALLET must be installed directly on the computer’s C:\ drive (and not in a subfolder). Nowhere in the documentation is this stated. As installed from the website, it is a command line-only program, which requires technical familiarity. Compounding that is a fairly short and abbreviated documentation. While the basics are more or less provided, they often require further investigation and exploration to fully understand (it is also possible to get MALLET to provide diagnostics on its analysis).
Beyond alienating novice users, the lack of documentation raises significant methodological issues. Relying only on MALLET’s documentation, a user would not see discussions of how many topics are appropriate, how many sampling iterations you should use, how it should be optimized, and how you can read diagnostic outputs. These variables have a significant effect on outputs. Poor documentation does not simply affect usability, but also whether the tool can be consistently used and its ability to generate the most useful and rigorous results available. There is a user mailing list for MALLET, but it can be somewhat intimidating for the novice user. For users coming from the humanities, a forum such as Digital Humanities Questions and Answers might be more appropriate, at least initially.
This issue has been remediated by community support, however. We have co-written an introduction in the Programming Historian 2 (with Scott Weingart), which has been linked from the MALLET page itself. Additionally, for more casual users, there is a JAVA GUI that can be fruitfully employed. You select your files or a directory, add a few parameters in drop-down menus or text boxes, and voila! — your topics are there before you. For working with undergraduates, this is the best way forward. Similarly, the SEASR MEANDRE workbench also incorporates topic modeling with MALLET, if you want to add it to a much more complicated workflow. By default SEASR exports to topic word clouds.
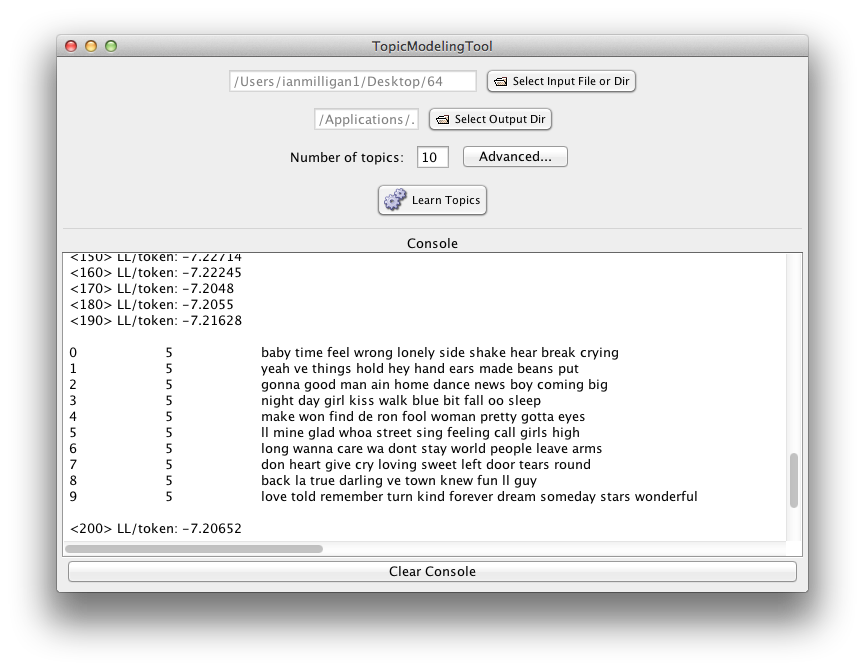
Figure 3: The Java Gui for MALLET, by David Newman and Arun Balagopalan.
If the tool itself is not perfect in terms of usability, a more significant point is that the “magical” results can be misleading. This is not a criticism of MALLET per se, but rather of the topic modeling methodology itself. The ‘correct’ number of topics is perhaps another issue that needs exploring from a humanistic perspective. MALLET needs to be told at the outset the target number of topics to search for. At the moment, the best way to proceed seems to be to run multiple analyses, varying the number of topics and looking for results that seem to fit “best” (however one defines that term), which would fit into what Trevor Owens calls a “generative approach“.[3] In which case, good practice might be to keep a kind of “lab notebook” detailing every combination of variables and the resulting outputs.
If MALLET isn’t exactly magic, it is, however, a wonderful “gateway drug” into the world of large-scale textual analysis. It just “seems to work,” which is a wonderful asset to bring to the table. As the digital humanities struggles with moving beyond the perception that we just count words (although, as Ted Underwood has pointed out in “Wordcounts are Amazing”, that’s a perfectly valid and engaging form of analysis), tools like topic modeling and MALLET help broaden our analysis. For historians, literary scholars, and other humanities researchers, MALLET is a valuable addition to your toolkit.
- [1]The full list of collaborators includes: Kedar Bellare, Gaurav Chandalia, Aron Culotta, Gregory Druck, Al Hough, Wei Li, David Mimno, David Pinto, Sameer Singh, Charles Sutton, Jerod Weinman, and Limin Yao, at University of Massachusetts Amherst, as well as contributions from Fernando Pereira, Ryan McDonald, and others at University of Pennsylvania.↩
- [2]Robert K. Nelson, “Mining the Dispatch: Introduction,” http://dsl.richmond.edu/dispatch/pages/intro.↩
- [3]Some further reading on this problem: Griffiths and Steyvers 2004 [pdf]; Mimno et al 2011 [pdf]; AlSumait et al. 2009 [pdf].↩