Historical Understanding in the Quantum Age
Joshua Sternfeld
The following remarks were delivered at the AHA Roundtable Session #83 Digital Historiography and Archives. They have been slightly modified and annotated for the Journal of Digital Humanities. Please note that the concepts presented here are a work-in-progress of a much larger project about digital historiography; I welcome additional comments or feedback. Finally, the statements and ideas expressed in this presentation do not necessarily reflect those of the National Endowment for the Humanities, or any federal agency.
What do the contours of conducting history in the twenty-first century look like and how are they changing? As we face a whirlwind of activity in reshaping historical methods, theory, and pedagogy, one thing is certain: The twenty-first-century historian has access to more varied and immense amounts of evidence, with the ability to draw freely from multimedia sources such as film and audio recordings, digitized corpora from antiquity to the present, as well as born digital sources such as websites, artwork, and computational data.
To get a sense of this abundance of evidence, let’s consider for a moment a very contemporary historical record, one that is undergoing perpetual creation and preservation. In April 2010, the Library of Congress signed an agreement with Twitter to preserve all 170 billion of the company’s tweets created between 2006 and 2010, and to continue to preserve all public tweets created thereafter. On a daily basis, that translates to roughly half a billion tweets sent globally.[1]
The case of preserving Twitter is a task that should excite both archivists and historians. For archivists, the primary technical and conceptual challenge is to provide timely access to such a massive corpus. As of last year, a single computational search by a lone researcher would have taken an unreasonable twenty-four hours to complete, which is why the Twitter archive remains dark for now.[2]
For historians, the challenge to analyze the Twitter corpus is equally if not more complex. Our traditional methods of close reading and deep contextualization fail to penetrate the social media network. To illustrate my point, let’s conduct a “close” reading of a single tweet. At 8:16 PM, on November 6, 2012 – election night – President Barack Obama tweeted “Four more years” followed by an image of him embracing Michelle Obama [Figure 1].
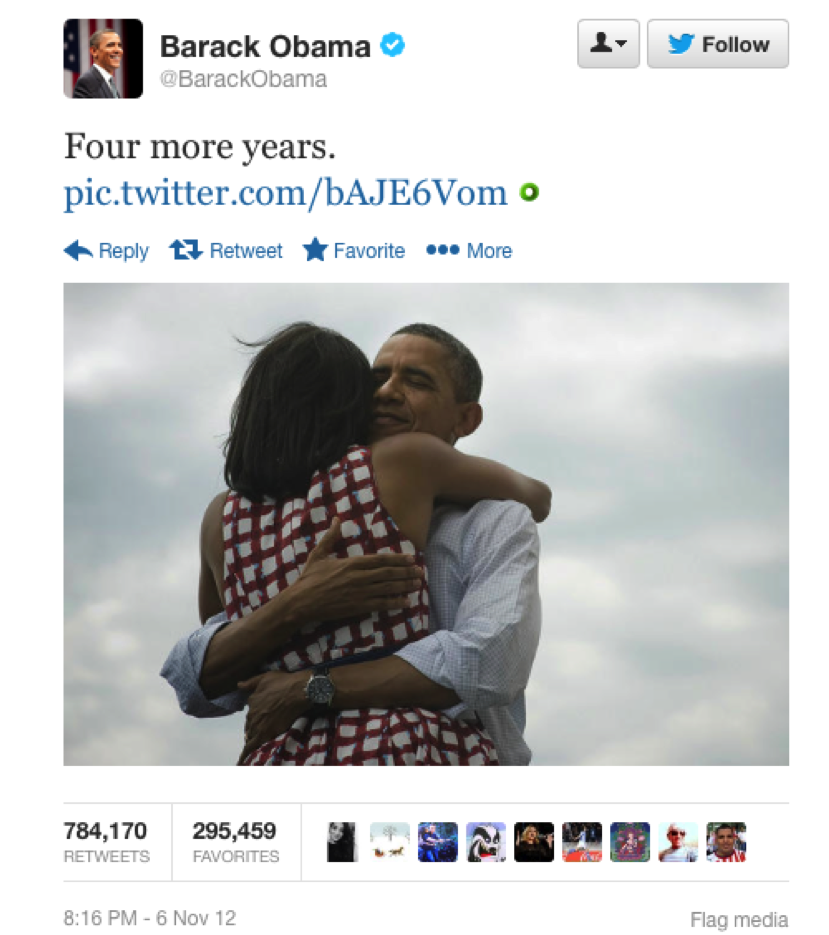
Figure 1: “Four More Years” Tweet Sent by President Barack Obama
Granted, we could analyze the visual composition of the image that was selected for the tweet that accompanied Obama’s re-election announcement, but the textual statement itself, “Four more years,” leaves little to the analytic imagination.[3]
But when you consider that this single tweet, containing a three-word sentence and an image, was retweeted 784,170 times and favorited nearly 300,000 times, you begin to get a sense of the vast network of people that lies just beneath the surface. As historians, we ought to be curious about the transmission of this tweet, including the demographics of who sent it, how quickly it circulated, and whether additional information was delivered as it raced through the Twittersphere. When you consider that at least thirty-one million additional tweets were sent on Election Day, you begin to realize that as historians, we will need to reorient our approach to studying the past so that it does not involve reading every one of those thirty-one million lines of text.
I have selected the Twitter corpus purely for illustrative purposes as just one of several possible examples of how digital media is transforming our relationship with historical materials. And of course, digital humanists are comfortable with conducting distant reading for a variety of corpora. The point I would like to make is that historians now face a decision that would have seemed inconceivable just a few years ago: to work with a limited set of sources from a circumscribed set of archives or special collections, or with materials that would be impossible to digest in a lifetime? In other words, historians must learn to maneuver in not just the era of the million books, but the million financial transaction records, web pages, census records, and a wealth of other data points.
In today’s talk, I would like to outline two concepts — scale and appraisal — that are critical for orienting how we work with an abundance of historical evidence made accessible by digital archives, libraries, and collections. To help us grasp the difference between digital and traditional modes of history, I propose we think about history in a quantum framework.
Just to be clear, I am not suggesting that a person could ever be in two places at once, or that historians will one day be able to “quantum leap” back in time with a companion named Al to rewrite the past! Rather, by placing history on a spectrum based on the scale of historical information, much like how our own physical environment can be placed on a scale from the subatomic to the astrophysical, we can reorient our understanding of human behavior, movement, networking, and activity.
Appraisal, to borrow a concept from archival theory, provides the framework to interpret the results of analysis conducted along the quantum spectrum. Whether we realize it or not, historians have always conducted appraisal of historical data. We have always assessed what information has value as evidence. And let’s face it; we have been notoriously poor at explicating our methods of working in the archives. We have had a tendency to brush aside a detailed explanation for how we search for and discover archival materials, organize those findings, and then present them in a cogent argument.
In the past, our physical limitations of what we could read and collect forced us to adapt our modes of argumentation and analysis by drawing upon inference, annotation, instinct and most of all experience as guides toward appraising evidence. The sheer size and scope of today’s digital sources demand a level of methodological rigor that we are not yet accustomed to applying.
My discussion about scale and appraisal of historical evidence, and digital historiography in general, is therefore grounded in a pursuit to define historical understanding in the digital age. Historical understanding explains how we learn about the past, authenticate evidence, and build arguments. In short, historical understanding answers the questions basic to all humanistic endeavors: how and why? Why did a phenomenon occur and why ought we to consider it significant? How do we explain a pattern of human behavior? These basic questions should be the guiding force behind all activities in digital history, from the building of new tools to interpretative projects. All too often, however, historical understanding has been drowned out in the noise of historical big data and the glitz of complex software, leaving skeptics to wonder whether digital history can fulfill its promise of revolutionizing the discipline. Applying methods of digital historical appraisal based on the scale of evidence sets us on a path towards validating conclusions and therefore contributing to historical understanding for a new era.
The Issue of Scale
Let’s begin with the concept of scale, where I will borrow liberally from the sciences.[4] There is a theory in physics that the Newtonian laws of our physical environment may not necessarily apply at the level of the extremely small or extremely large.
The properties of gravity, mass, acceleration, and so forth begin to break down when you consider subatomic particles too small to detect using conventional instruments. Furthermore, mystifying substances such as dark matter seem to disrupt these same properties at an astrophysical level. While there are scientists who are working towards a unifying theory, for the time being these levels, and the laws that govern them, remain distinct.
I would argue that history operates in a similar fashion, with different levels of historical information, or data, with which one can choose to work. Up until very recently, the vast majority of historical work operated at what I call the Newtonian level, that is, the level at which a single historian can synthesize data into a coherent narrative argument. A basic definition of history, the study of change over time, reflects a Newtonian mindset:
History: a continuous, systematic narrative of past events as relating to a particular people, country, period, person, etc., usually written as a chronological account; chronicle[5]
Much like Newtonian physics, Newtonian history has been incredibly successful in building an understanding of the past, particularly when accounting for the laws of causality and the interactions of individuals and societies.
Just as the principles behind inertia inform us that an object in motion tends to stay in motion or an object at rest stays at rest, we have developed over time principles of rhetoric and logic that allow us to work within a degree of epistemological certainty. History in the modern era, in other words, works best when investigating the likelihood that Event/Person/Society A may or may not have contributed to Outcome B, however abstract that outcome may be. My point is that the type of linear narrative history that has developed over the course of centuries has depended in part upon the degree of access to historical data, our ability to synthesize that data into a cogent argument, and our modes of representation.
What happens to the fabric of historical work if we extend our access to information along a quantum spectrum?
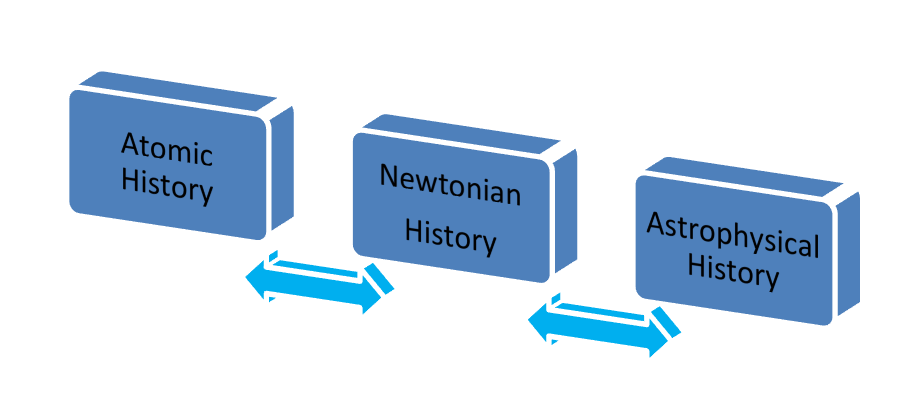
Figure 2: Quantum Spectrum of History
We begin to open new levels at which we can do history [Figure 2]. On one end of the spectrum, there is the study of a micro piece of evidence, much as we have always done but at a level of precision that may not have been previously possible. We can study the digitized manifest of a slave ship, or a criminal trial in London, each with a rich history worthy of unraveling.[6]
Digital technologies have also allowed historians to probe the materiality of artifacts in ways that have unearthed new findings. Methods of spectral analysis, for example, have detected pigments underneath parchment, such as was the case with the discovery of the Archimedes Codex[7], or the revelation that Thomas Jefferson originally intended for the word “citizens” to be “subjects” in the drafting of the Declaration of Independence.[8]
Returning to our example of Twitter, we might consider the single tweet. While earlier our close reading of Obama’s tweet seemed one-dimensional, there is in fact an extraordinary amount of visible and hidden information surrounding the text message that one can extract from a published tweet that conveys a history unto itself. According to the Library of Congress, each tweet can contain 50 unique pieces of information, or metadata, such as the time it was published, the location from where the tweet was sent, and information about the person who sent it [Figure3].[9]
Figure 3: Provenancial Metadata of a Tweet
Besides information contained within the tweet, we may wonder about external circumstances surrounding its creation. For example, exactly where was Obama when he sent the announcement? Did he even compose it himself? Metadata can get us part of the way toward reconstructing the context behind the creation of a tweet, but we likely will need other sources of information outside Twitter, such as journalistic accounts of election night, to assemble a richer portrait of a moment in time.
On the other end of the spectrum, as suggested earlier, are the millions of tweets that may be connected to a single event, person, or community. Take, for example, the following visualization of 2012 Election Day tweets color coded by the intuited political party orientation of the text and geo-referenced according to where the tweets were sent [Figure 4].[10].
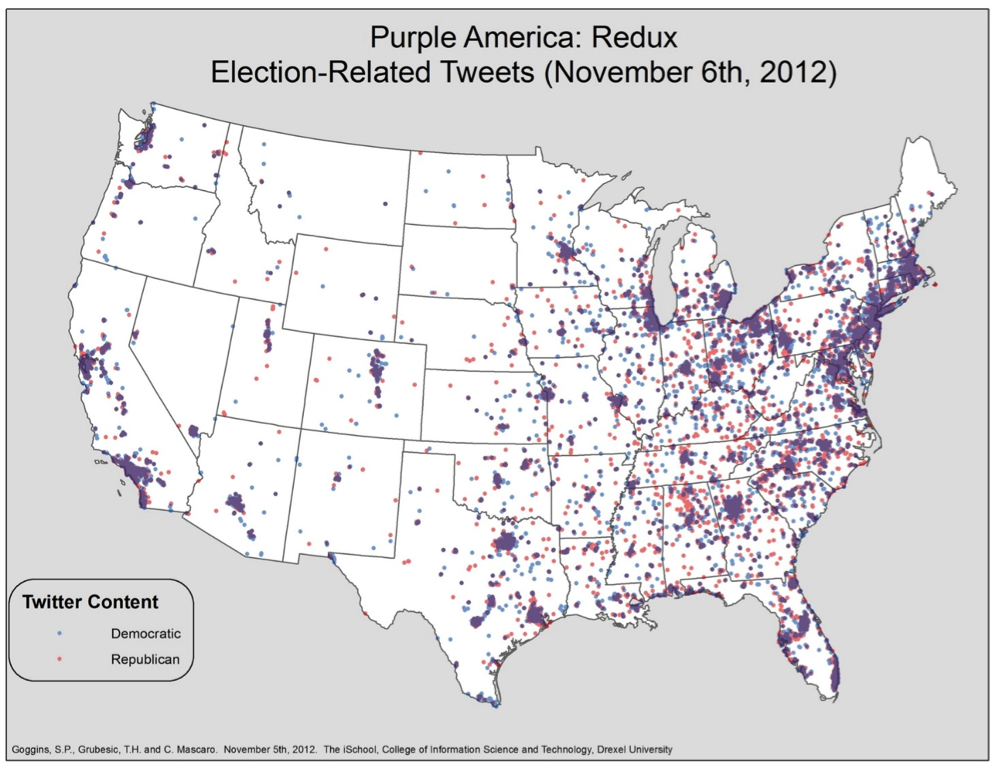
Figure 4: Visualization of 2012 Election Day Tweets by Political Party and Location
Besides tweets, this extreme end of the spectrum also includes massive databases, storehouses of information of all varieties from complex texts, to databases filled with statistics, to non-textual media. One ship’s manifest is combined with nearly 35,000 others to form the Trans-Atlantic Slave Trade Database[11] and one London trial is collated with over 197,000 others conducted between 1674 and 1913 to form The Proceedings of the Old Bailey.[12] For the remainder of my talk, I want to focus on this end of the historical data spectrum.
As you may imagine, when you move into the realm of the vast, the traditional laws governing historical understanding begin to breakdown. Take the graphs produced by the scientists behind the Google Ngram Viewer, an analytic tool that counts the frequency of words and phrases across a portion of the millions of books scanned by Google. The scientists have demonstrated, for example, that by tracing the appearance of selected artists’ names we can generate graphs that reveal periods of state censorship, revealing that between 1933 and 1945 National Socialists in Germany suppressed discussion of artists deemed Jewish or degenerate.[13] On the one hand, these graphs are compelling for suggesting the effectiveness of the censorship campaign. On the other hand, they don’t necessarily reveal anything historians don’t already know, and they certainly don’t explain the causes behind the statistical trend. We have no idea from a graph alone who enforced the artist ban or the rationale behind its enforcement. In other words, big data visualizations such as those produced by the Ngram Viewer wipe away any remnant of historical causality. If you feel a sense of unease at this prospect, you are not alone.[14]
Our unease should suggest that we need to retake the reigns from the computer scientists and build a new framework for working with big historical data, one that can harness computational power while exploring deeper, less obvious connections. But where do we begin?
Returning to the physics analogy, the massive particle accelerator known as the Large Hadron Collider built in Switzerland was designed in part to test for the existence of the Higgs Boson, or “God particle,” by smashing together atoms and computationally sifting through the enormous amounts of resultant data. Of course, before the Large Hadron Collider could be trusted to produce reliable data, it needed to be calibrated and recalibrated according to stringent standards established by the scientific community. I would argue that digital history is lodged in a perpetual state of experimentation, smashing data together to see what is produced, but not yet at a stage of calibration to produce a substantial body of worthwhile evidence. We are simply not yet accustomed to working at different scales of data, and a great deal of calibration is still required.
Why is this the case? Why don’t the laws of Newtonian history apply at different scales? The reason is that we have yet to calibrate the digital tools and methods according to historiographical questions both old and new that are suitable for investigation. When we transition into a new scale of data, we naturally introduce variables that have the potential for invalidating our findings. Skeptics declare – often rightly so — that historical data is incomplete, fuzzy, and ill-suited for methods that operate on a presumption of scientific certainty. They also argue that the representational properties of digital media can supply a false sense of objectivity by denying data proper contextualization.
There is a lot of validity to these criticisms. More often than not, historical data sets are messy, and vulnerable to an assortment of critical attacks. Only by applying our skills of critical analysis will we feel comfortable participating in the creation and use of digital tools such as the Ngram Viewer. My point is that we must use our natural critical tendencies – in short, our skepticism — to calibrate our data sets and the methods used to interrogate them. Only then will we begin to fulfill what Alan Liu calls a “new interpretive paradigm” in the digital humanities, and digital history in particular.[15] This brings me to digital historical appraisal, which, in a nutshell, is the process by which we profile a dataset.
Digital Historical Appraisal
As I suggested earlier, we rarely stop to appreciate the complex analytic assessment that occurs during our appraisal of archival materials. Who has the time to acknowledge systematically the reams of materials that we reject before we stumble across the items we deem as possessing evidentiary value? Archivists would explain that evidentiary value derives from basic archival principles such as respects du fonds, which assures us that the original order of the materials has been preserved. As my fellow presenters discuss further, the endeavor of organizing archival materials is an intellectual, subjective exercise. The decision-making process to arrange and describe a collection contributes to the collection’s contextualization and influences historians’ access to materials.
Contextualization also applies in the digital environment, although the risk of separating a digital record or artifact from its provenance raises the stakes considerably. Whereas historians feel comfortable assessing a collection defined in linear feet, they have yet to find reliable methods for assessing collections defined in terabytes. The absence of visual cues thanks to cold, monolithic servers and hard drives, however, need not deter historians from gaining greater intellectual control over a digital collection. We simply need new methods to apply historical appraisal.
There are two elements vital to conducting an appraisal: scope and provenance. As with analog materials, we want to consider what digital materials have been selected for an archive or collection. By determining which items were kept and which ignored or discarded, we can begin to construct the contextual boundaries, or scope, of a collection. Besides the selection of materials, we also must account for whether one can trace data back to their point of origin, what archivists call provenance. For materials that were originally in an analog format, we would want to know their original archival location, whereas for born digital information we may want to know under what conditions data are generated. Without such information, or metadata, digital records pose a greater risk of becoming de-contextualized, that is, they have the potential to lose the value they may possess according to their relationship to other records. Just as we would be wary to trust a lone document that has been divorced from its archival folder or box, a digital item without metadata places additional strain on validating its authenticity and trustworthiness.
Think of how we might treat Obama’s tweet if we didn’t have the unique markers that signal that he was the author, or the time and location from which the tweet was sent [Figure 5].
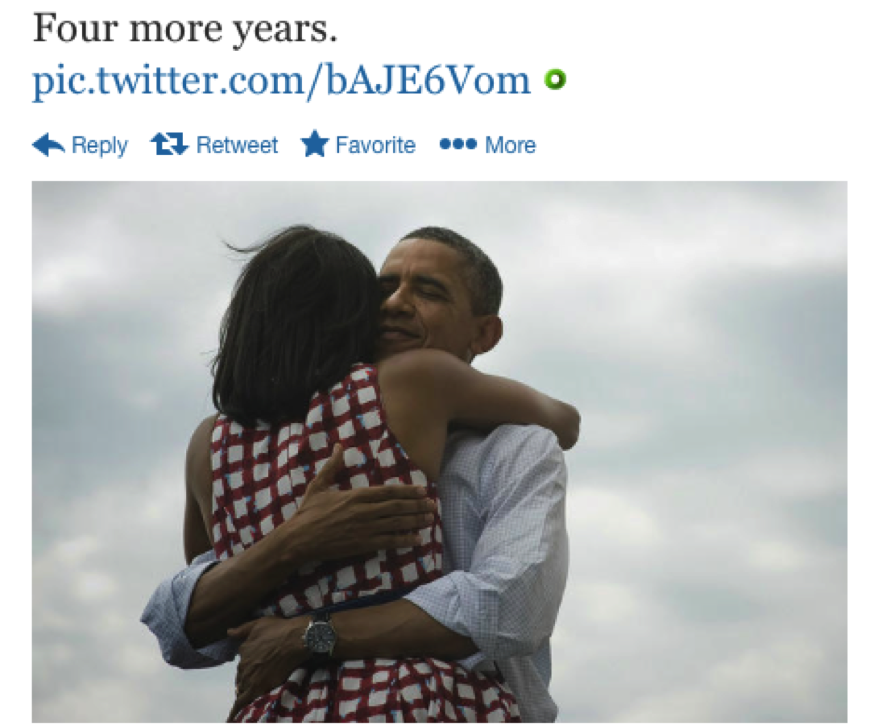
Figure 5: Obama’s Tweet Minus Provenancial Metadata
Would we still trust it as reliable evidence? Consider also the provenance of a tweet. Although we may have a record of a tweet’s original time posting and possibly geographic point of origin, tracking its distribution in subsequent retweets, quotes, and conversations introduces a host of challenges that requires a combination of precision, deftness, and creativity in critical thought.
We can also expand our discussion of provenance beyond the tweet in question. Consider that the historical value of tweets often comes from referencing events, conversations, and websites that have a provenancial record outside the Twitter communication stream, as you can see in this random sampling of tweets related to the AHA conference [Figure 6].
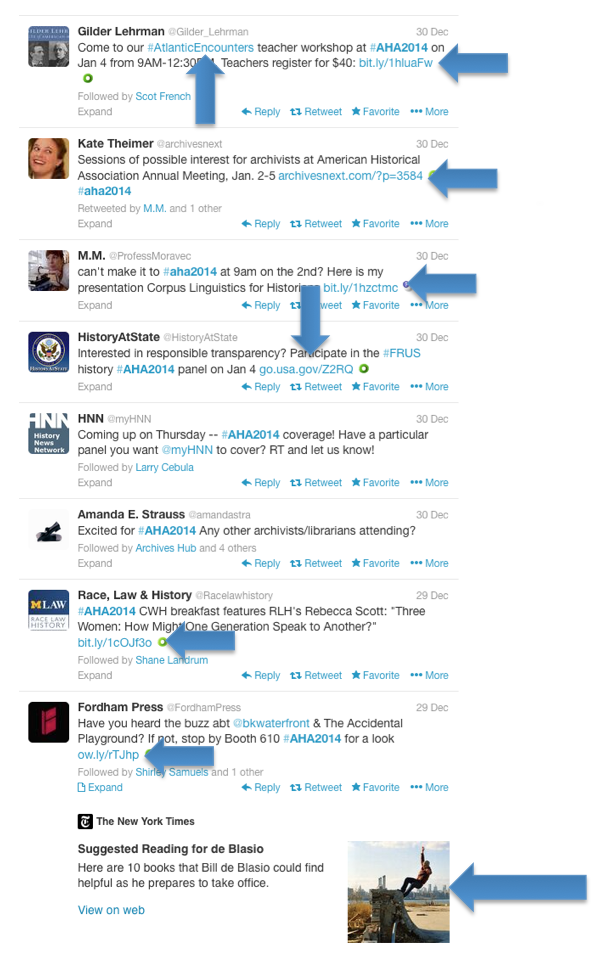
Figure 6: Sample Twitter Stream from #AHA2014. Arrows Point to External Links and Media
In other words, historians may be interested not just in the provenance of the tweet, but the vast corpus of materials such as websites, reports, slides, and other digital materials associated with those tweets.
There are researchers in other disciplines who are conducting experiments to answer these very questions in information science fields such as socioinformatics and alt-metrics. My point is that historians must play a role in this research, as we realize that the digital media of today becomes the artifacts of tomorrow. Participation begins with what historians do best, applying a critical framework to appraise historical data.
Thankfully, we are beginning to see examples of what digital historical appraisal may look like. Pragmatically, the methods of appraisal, and even the modes for explaining these methods will depend on the size of the collection and the nature of the project. At times, appraisal may require algorithmic computations measuring particular elements of the data. One such example worth noting is the Trans-Atlantic Slave Trade Database. The lead historian on the project, David Eltis, wrote an essay entitled “Coverage of the Slave Trade” that outlines the quantitative methods employed to estimate the data set’s completeness. Drawing upon accepted evidence from the field, Eltis contends that the nearly 35,000 Trans-Atlantic voyages documented in the database can help scholars “infer the total number of voyages carrying slaves from Africa,” by concluding that the database represents “some trace of 81 percent of the vessels that embarked captives.”[16] (Note that the author elected to communicate his appraisal of a complex database using an “analog” format –the essay– that ought to remind us that visualizations may require just as much written explanatory text as a scholarly article or monograph.) In short, relying upon a combination of statistical analysis and historiography, the developers generated a claim about their database’s representativeness. The interplay between historiography, appraisal, and digital modes of representations will require much more consideration as we continue to shape digital historiography.
Digital Historiography
At its core, digital history has enhanced the capacity of historians to investigate the past at different levels of inquiry. By considering the concepts of scale and appraisal in tandem, my hope is that the field will move toward a pragmatic approach to conducting digital history. The size and scale of information will determine, in the end, the mode of inquiry and the results that are possible.
In previous work, I labeled this pragmatic approach to conducting history digital historiography, a term that has had some bearing on the title of the AHA session. I defined digital historiography as “the interdisciplinary study of the interaction of digital technology with historical practice.”[17]
This definition provided an opening to consider digital history at every stage of production by encouraging practitioners to consider how digital historical understanding should determine which theories and methods to adapt for a given pursuit.
Digital historiography recognizes that historical understanding possesses fundamentally different qualities in analog versus digital environments. Instead of adapting the historiographical questions of yesterday to the tools and methods of today, we ought to recognize that digital history will yield new understanding, new modes of inquiry that can complement our Newtonian tendencies to want to explain causes and effects.
In short, we can characterize digital historiography as mediating among the different levels of quantum history. By refining our ability to appraise historical data, we will become adept at moving back and forth among the levels. In Twitter terms, this would be the negotiation of going from a single tweet, to a circumscribed network of tweets such as a professional society or state, to the national and even global expanse of tweets, and back again [Figure 7].
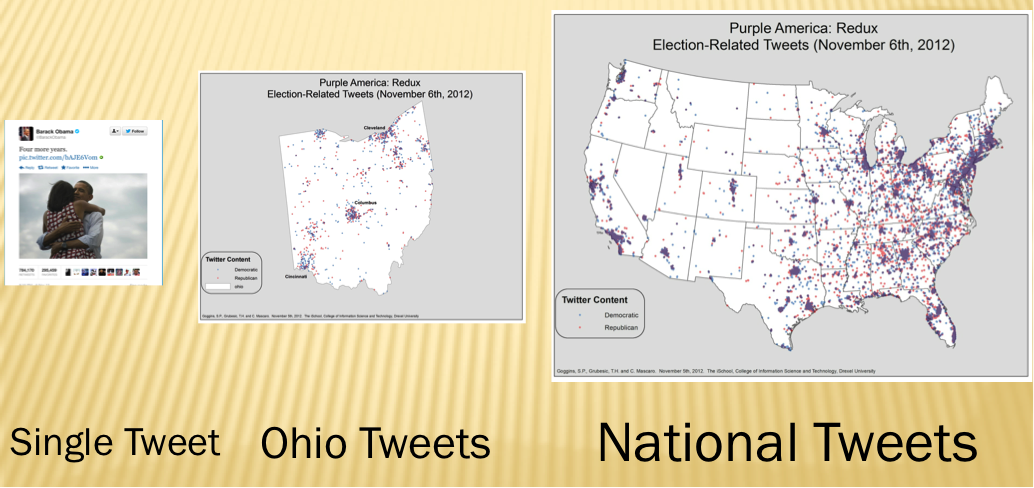
Figure 7: Spectrum of 2012 Election Day Tweets
How does each level inform the other and where are the connections that permit us to trace activity within the network?
In terms of the Ngram Viewer and similar tools, a query produced at a big data level may compel us to return to the underlying sources for additional close reading and analysis. In their macro-analysis of Victorian literature, Fred Gibbs and Dan Cohen suggest developing a method that can accommodate both the macro and micro sets of data:
Any robust digital research methodology must allow the scholar to move easily between distant and close reading, between the bird’s eye view and the ground level of the texts themselves…. The hybrid approach we have briefly described here can help scholars determine exactly on which books, chapters, or pages to focus, without relying solely on sophisticated algorithms that might filter out too much. Flexibility is crucial, as there is no monolithic digital methodology that can be applied to all research questions.[18]
Gibbs and Cohen are correct in asserting that any viable methodology will require “flexibility” in moving among the different levels of data. What their preliminary findings do not explicate is how the digital historian achieves such flexibility. What sort of intellectual rigor, whether represented by shared standards, practices, or theories, must be in place to provide the integrity necessary to sustain an argument from one level to the next?
The answer, as I hope my talk begins to outline, can be found by returning to the relationship between historians and archivists. Only by understanding one another’s domain can we begin to bridge the disciplinary divide that will enable us to pinpoint the bits of data or texts that warrant our attention. In other words, we need to develop creative methods for reducing a million books down to a more manageable set of materials.
Historians and archivists, therefore, ought to concern themselves with the areas of transition, the connections between macro datasets and those that can be consumed at a human level [Figure 8].
Figure 8
Liu writes: “[T]he interpretive or analytical methods at the two ends of the scale, macro and micro, are anything but seamless in their relationship…. It may be predicted that one of the next frontiers for the digital humanities will be to discover technically and theoretically how to negotiate between distant and close reading.”[19] This challenge requires knowledge of how digital information is managed, organized, and made accessible as well as deep mastery of relevant historiographical matters. It requires the ability to contextualize datasets at scales that historians may not be accustomed to analyzing. In short, it requires coordination among historians, archivists, and other information professionals. By appraising more precisely the size, scope, and completeness of a given collection of historical data, we will begin to construct a pathway towards posing and answering some of our most complex and enduring questions about the human condition.
Originally published by Joshua Sternfeld on January 20, 2014. Revised for the Journal of Digital Humanities in August 2014.
References
Aiden, Aviva Presser, and Jean-Baptiste Michel. Uncharted: Big Data as a Lens on Human Culture. Riverhead Hardcover, 2013.
Black, Alan, Christopher Mascaro, Michael Gallagher, and Sean P. Goggins. “Twitter Zombie: Architecture for Capturing, Socially Transforming and Analyzing the Twittersphere.” In Proceedings of the 17th ACM international conference on Supporting group work, 229-38, 2012.
Eltis, David, and Martin Halbert. “The Trans-Atlantic Slave Trade Database.” Emory University, 2009. http://www.slavevoyages.org/tast/index.faces.
Gibbs, Frederick W., and Daniel J. Cohen. “A Conversation with Data: Prospecting Victorian Words and Ideas.” Victorian Studies 54, no. 1 (2011): 69-77.
Goggins, S.P., T.H. Grubesic, and C. Mascaro. “Election 2012 – Election Day Partisan Tweets across the USA and in Ohio.” Drexel University, 2012. http://www.groupinformatics.org/election2012b.
Hitchcock, Tim, Robert Shoemaker, and Clive Emsley. “The Proceedings of the Old Bailey: London’s Central Criminal Court, 1674 to 1913.” University of Hertfordshire and University of Sheffield, 2013. http://www.oldbaileyonline.org.
Library of Congress. “Subject to Change.” In Wise Guide: Library of Congress, 2010. http://www.loc.gov/wiseguide/aug10/subject.html.
———. “Update on Twitter Archive at the Library of Congress.” 2013. http://www.loc.gov/today/pr/2013/files/twitter_report_2013jan.pdf.
Liu, Alan. “The State of the Digital Humanities: A Report and a Critique.” Arts & Humanities in Higher Education II, no. 1-2 (2011): 8-41.
Michel*, Jean-Baptiste, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, William Brockman, The Google Books Team, et al. “Quantitative Analysis of Culture Using Millions of Digitized Books.” Science (2010).
Netz, Reviel, and William Noel. The Archimedes Codex: How a Medieval Prayer Book Is Revealing the True Genius of Antiquity’s Greatest Scientist. Da Capo Press, 2009.
Nunberg, Geoffrey. “Counting on Google Books.” The Chronicle Review (2010). Published electronically December 16, 2010. http://chronicle.com/article/Counting-on-Google-Books/125735.
Osterberg, Gayle. “Update on the Twitter Archive at the Library of Congress.” In Library of Congress Blog, edited by Erin Allen. Washington, D.C.: Library of Congress, 2013. http://blogs.loc.gov/loc/2013/01/update-on-the-twitter-archive-at-the-library-of-congress/.
Randall, Lisa. Knocking on Heaven’s Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern World. HarperCollins, 2012.
Sternfeld, Joshua. “Archival Theory and Digital Historiography: Selection, Search, and Metadata as Archival Processes for Assessing Historical Contextualization.” The American Archivist 74, Fall/Winter (2011): 544-75.
- [1]Gayle Osterberg. “Update on the Twitter Archive at the Library of Congress.” Library of Congress Blog, 2013, http://blogs.loc.gov/loc/2013/01/update-on-the-twitter-archive-at-the-library-of-congress/. Accessed July 19, 2014.↩
- [2]Library of Congress, “Update on Twitter Archive at the Library of Congress,” (2013), http://www.loc.gov/today/pr/2013/files/twitter_report_2013jan.pdf. Accessed July 19, 2014.↩
- [3]Citing a single “original” tweet is an exercise in online sleuthing. In theory, the tweet may be accessed at @BarackObama’s profile — https://twitter.com/BarackObama — although the user may have to wade through over 12,000 tweets to locate it. Obama’s Organizing for Action references the tweet here: https://twitter.com/BarackObama/status/266031293945503744. The image used for this presentation was accessed January 2014, but the tweet seems to continue to have life. According to Twitter’s “Golden Tweets” it has been retweeted 810,000+ times and favorited 300,000+ times: https://2012.twitter.com/en/golden-tweets.html.↩
- [4]I owe much of my (admittedly coarse) understanding of quantum mechanics to Lisa Randall, Knocking on Heaven’s Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern World (HarperCollins, 2012).↩
- [5]http://dictionary.reference.com/browse/HISTORY?s=t. Accessed July 19, 2014.↩
- [6]For typical examples of both, see the Register of Africans from the schooner “Virginie” found in the Trans-Atlantic Slave Trade Database, http://www.slavevoyages.org/tast/resources/images.faces;jsessionid=2E7D3E3977482C7211A84232E985AC5A, and a murder trial held on July 4, 1730: http://www.oldbaileyonline.org/images.jsp?doc=173007040011. Accessed July 19, 2014.↩
- [7]For the complete story of this fascinating discovery, see Reviel Netz and William Noel, The Archimedes Codex: How a Medieval Prayer Book Is Revealing the True Genius of Antiquity’s Greatest Scientist (Da Capo Press, 2009).↩
- [8]An explanation of which can be found here: Library of Congress. “Subject to Change.” Wise Guide, 2010, http://www.loc.gov/wiseguide/aug10/subject.html. Accessed July 19, 2014.↩
- [9]“Update on Twitter Archive at the Library of Congress.”↩
- [10] S.P. Goggins, T.H. Grubesic, and C. Mascaro, “Election 2012 – Election Day Partisan Tweets across the USA and in Ohio,” (Drexel University, 2012), http://www.groupinformatics.org/election2012b. Accessed July 19, 2014. For more information on how these Twitter visualizations were generated, see: Alan Black et al., “Twitter Zombie: Architecture for Capturing, Socially Transforming and Analyzing the Twittersphere,” in Proceedings of the 17th ACM international conference on Supporting group work (2012).↩
- [11]David Eltis and Martin Halbert, “The Trans-Atlantic Slave Trade Database,” (Emory University, 2009), http://www.slavevoyages.org/tast/index.faces. Accessed July 19, 2014.↩
- [12]Tim Hitchcock, Robert Shoemaker, and Clive Emsley, “The Proceedings of the Old Bailey: London’s Central Criminal Court, 1674 to 1913,” (University of Hertfordshire and University of Sheffield, 2013), http://www.oldbaileyonline.org. Accessed July 19, 2014.↩
- [13]This argument first appeared in the article that introduced the concept of “Culturomics”: Jean-Baptiste Michel* et al., “Quantitative Analysis of Culture Using Millions of Digitized Books,” Science (2010). A more comprehensive discussion of the National Socialist censorship campaign can be found in the authors’ follow-up book: Aviva Presser Aiden and Jean-Baptiste Michel, Uncharted: Big Data as a Lens on Human Culture, (Riverhead Hardcover, 2013). Chapter 5.↩
- [14]See, for example, Geoffrey Nunberg, “Counting on Google Books,” The Chronicle Review (2010), http://chronicle.com/article/Counting-on-Google-Books/125735. Accessed July 19, 2014.↩
- [15]Alan Liu, “The State of the Digital Humanities: A Report and a Critique,” Arts & Humanities in Higher Education II, no. 1-2 (2011). 21.↩
- [16]David Eltis. “Construction of the Trans-Atlantic Slave Trade Database: Sources and Methods.” http://www.slavevoyages.org/tast/database/methodology-02.faces. Accessed July 19, 2014.↩
- [17]Joshua Sternfeld, “Archival Theory and Digital Historiography: Selection, Search, and Metadata as Archival Processes for Assessing Historical Contextualization,” The American Archivist 74, Fall/Winter (2011).↩
- [18]Frederick W. Gibbs and Daniel J. Cohen, “A Conversation with Data: Prospecting Victorian Words and Ideas,” Victorian Studies 54, no. 1 (2011). p.76.↩
- [19]Liu, “The State of the Digital Humanities: A Report and a Critique.” 27.↩